AWS Certified Data Engineer - Associate - Exam Simulator
DEA-C01
Prepare for your AWS Certified Data Engineer - Associate exam with our practice exam simulator. Featuring real exam scenarios, detailed explanations, and instant feedback to boost your confidence and success rate.
Questions update: Nov 13 2024
Questions count: 3312
Example questions
Domains: 4
Tasks: 17
Services: 70
The AWS Certified Data Engineer - Associate (DEA-C01) exam is recognized as a demanding certification that validates a candidate's expertise in managing and optimizing data-driven workflows within the AWS ecosystem. While this exam is geared towards professionals with a background in data engineering, it is by no means an easy feat and requires a thorough understanding of both foundational and advanced AWS data services.
The DEA-C01 exam covers a broad range of topics, including but not limited to, data ingestion, transformation, storage, and visualization within AWS. Candidates must demonstrate a solid grasp of essential AWS data services such as Amazon Redshift, Glue, S3, and Kinesis, along with a deep understanding of how to architect and maintain scalable, secure, and high-performing data pipelines.
A critical component of the exam focuses on data processing frameworks like Apache Spark and Hadoop, as well as an understanding of database services, both relational (RDS, Aurora) and non-relational (DynamoDB). Additionally, the exam tests the candidate's ability to apply machine learning workflows using services like Amazon SageMaker within a data engineering context.
Security and compliance are integral to the exam, emphasizing the need for candidates to understand AWS's shared responsibility model and implement best practices for data governance, encryption, and access management. Services such as IAM, KMS, and AWS Lake Formation are frequently tested to ensure candidates can securely manage data at scale.
In this exam, candidates are also expected to distinguish between various data storage and retrieval solutions, optimizing them based on specific use cases and cost considerations. This includes knowing when to utilize services like S3 for unstructured data versus using Redshift for structured data analytics.
Overall, the questions in the DEA-C01 exam are designed to challenge both theoretical knowledge and practical application, with scenarios that require candidates to design, implement, and optimize complex data architectures. While the exam avoids overly complicated wording, the difficulty lies in the depth of knowledge requi
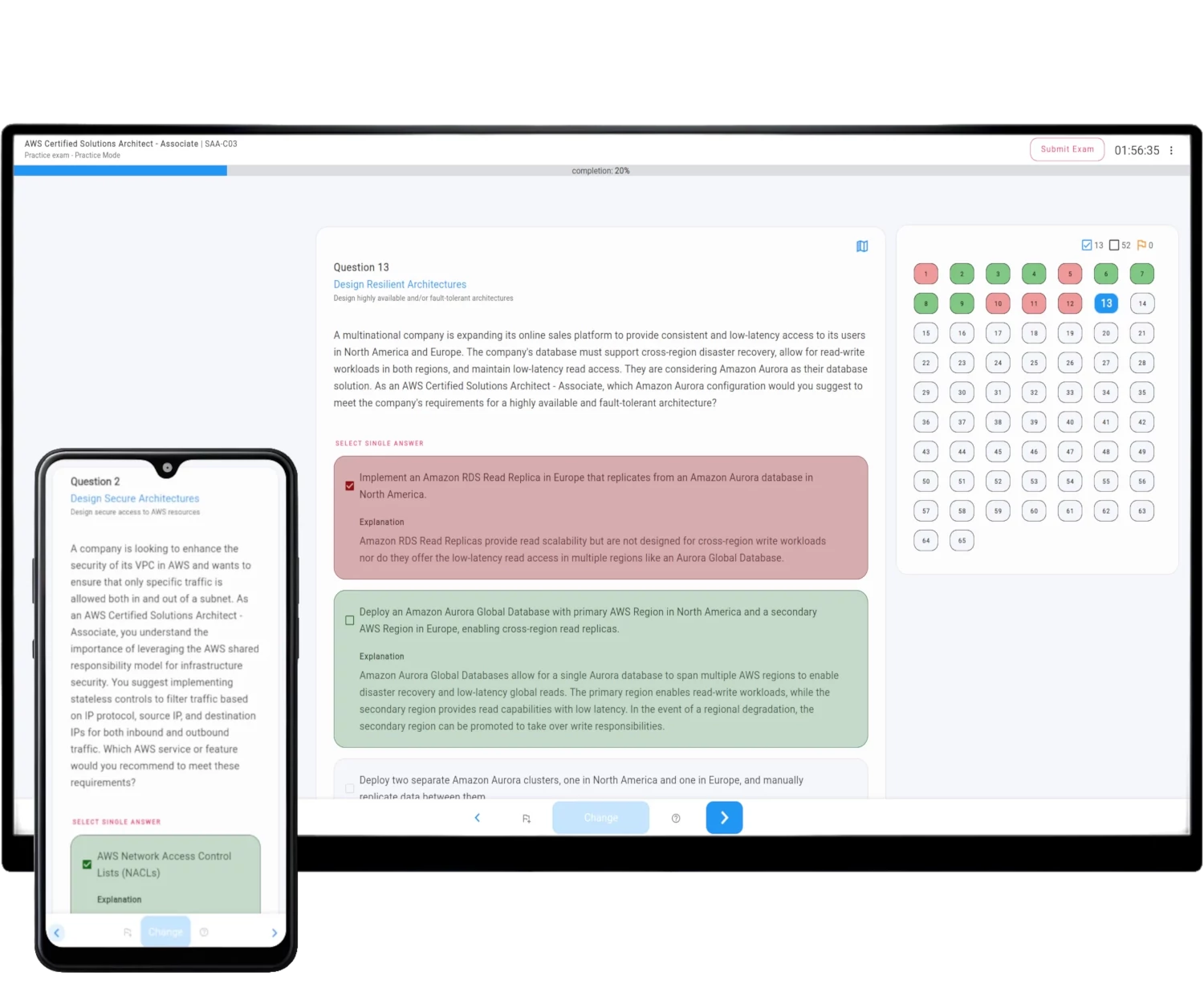
How AWS Exam Simulator works
The Simulator generates on-demand unique practice exam question sets fully compatible with the selected AWS Official Certificate Exam.
The exam structure, difficulty requirements, domains, and tasks are all included.
Rich features not only provide you with the same environment as your real online exam but also help you learn and pass AWS Certified Data Engineer - Associate - DEA-C01 with ease, without lengthy courses and video lectures.
See all features - refer to the detailed description of AWS Exam Simulator description.
| Exam Mode | Practice Mode | |
|---|---|---|
| Questions count | 65 | 1 - 75 |
| Limited exam time | Yes | An option |
| Time limit | 130 minutes | 10 - 200 minutes |
| Exam scope | 4 domains with appropriate questions ratio | Specify domains with appropriate questions ratio |
| Correct answers | After exam submission | After exam submission or after question answer |
| Questions types | Mix of single and multiple correct answers | Single, Multiple or Both |
| Question tip | Never | An option |
| Reveal question domain | After exam submission | After exam submission or during the exam |
| Scoring | 15 from 65 questions do not count towards the result | Official AWS Method or mathematical mean |
Exam Scope
The Practice Exam Simulator questions sets are fully compatible with the official exam scope and covers all concepts, services, domains and tasks specified in the official exam guide.
For the AWS Certified Data Engineer - Associate - DEA-C01 exam, the questions are categorized into one of 4 domains: Data Ingestion and Transformation, Data Store Management, Data Operations and Support, Data Security and Governance, which are further divided into 17 tasks.
AWS structures the questions in this way to help learners better understand exam requirements and focus more effectively on domains and tasks they find challenging.
This approach aids in learning and validating preparedness before the actual exam. With the Simulator, you can customize the exam scope by concentrating on specific domains.
Exam Domains and Tasks - example questions
Explore the domains and tasks of AWS Certified Data Engineer - Associate - DEA-C01 exam, along with example questions set.